Hash 表
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
为何能够通过 key 快速取出 value 呢? 原因在于 哈希算法(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
hash = hashfunc(key)
index = hash % array_size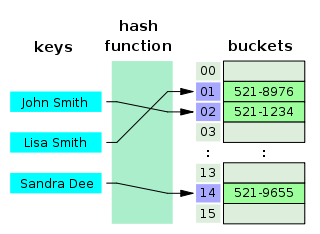
但是!哈希算法有个 Hash 冲突 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 链地址法。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。
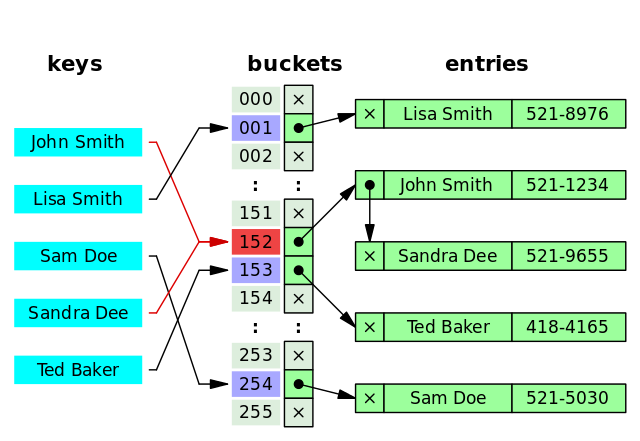
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,InnoDB 存储引擎中存在一种特殊的“自适应哈希索引”(Adaptive Hash Index),自适应哈希索引并不是传统意义上的纯哈希索引,而是结合了 B+Tree 和哈希索引的特点,以便更好地适应实际应用中的数据访问模式和性能需求。自适应哈希索引的每个哈希桶实际上是一个小型的 B+Tree 结构。这个 B+Tree 结构可以存储多个键值对,而不仅仅是一个键。这有助于减少哈希冲突链的长度,提高了索引的效率。
关于 Adaptive Hash Index 的详细介绍,可以查看 MySQL 各种“Buffer”之 Adaptive Hash Index 这篇文章。
既然哈希表这么快,为什么 MySQL 没有使用其作为索引的数据结构呢? 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
试想一种情况:
SELECT * FROM tb1 WHERE id < 500;在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。