读写分离
什么是读写分离?
读写分离基于主从复制,主要是为了将对数据库的读写操作分散到不同的数据库节点上。 能够小幅提升写性能,大幅提升读性能。
一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。这样的架构实现起来比较简单,并且也符合系统的写少读多的特点。
为什么要用读写分离
当数据库中的读并发请求太多的时候,数据库会支撑不住。读写分离就是用来解决数据库的读性能瓶颈的。
如何实现读写分离?
实现读写分离的步骤:
- 部署多台数据库,选择其中的一台作为主数据库,其他的一台或者多台作为从数据库。
- 保证主数据库和从数据库之间的数据是实时同步的,这个过程也就是我们常说的主从复制。
- 系统将写请求交给主数据库处理,读请求交给从数据库处理。
落实到项目本身的话,常用的方式有两种:
1. 代理方式
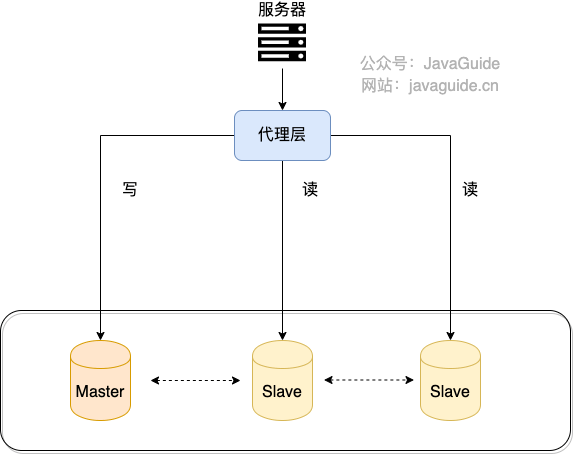
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
提供类似功能的中间件有 MySQL Router(官方, MySQL Proxy 的替代方案)、Atlas(基于 MySQL Proxy)、MaxScale、MyCat。
关于 MySQL Router 多提一点:在 MySQL 8.2 的版本中,MySQL Router 能自动分辨对数据库读写/操作并把这些操作路由到正确的实例上。这是一项有价值的功能,可以优化数据库性能和可扩展性,而无需在应用程序中进行任何更改。具体介绍可以参考官方博客:MySQL 8.2 – transparent read/write splitting。
2. 组件方式
在这种方式中,我们可以通过引入第三方组件来帮助我们读写请求。
这也是我比较推荐的一种方式。这种方式目前在各种互联网公司中用的最多的,相关的实际的案例也非常多。如果你要采用这种方式的话,推荐使用 sharding-jdbc ,直接引入 jar 包即可使用,非常方便。同时,也节省了很多运维的成本。
你可以在 shardingsphere 官方找到 sharding-jdbc 关于读写分离的操作。