使用数据库生成分布式ID
数据库主键自增
这种方式就比较简单直白了,就是通过关系型数据库的自增主键产生来唯一的 ID。
数据库主键自增
以 MySQL 举例,我们通过下面的方式即可。
1.创建一个数据库表。
CREATE TABLE `sequence_id` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`stub` char(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;stub 字段无意义,只是为了占位,便于我们插入或者修改数据。并且,给 stub 字段创建了唯一索引,保证其唯一性。
2.通过 replace into 来插入数据。
BEGIN;
REPLACE INTO sequence_id (stub) VALUES ('stub');
SELECT LAST_INSERT_ID();
COMMIT;插入数据这里,我们没有使用 insert into 而是使用 replace into 来插入数据,具体步骤是这样的:
-
第一步:尝试把数据插入到表中。
-
第二步:如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
这种方式的优缺点也比较明显:
- 优点:实现起来比较简单、ID 有序递增、存储消耗空间小
- 缺点:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
数据库号段模式
数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,ID 需求比较大的时候,肯定是不行的。
如果我们可以批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了!这也就是我们说的 基于数据库的号段模式来生成分布式 ID。
数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的Tinyid 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
以 MySQL 举例,我们通过下面的方式即可。
1. 创建一个数据库表。
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(10) NOT NULL COMMENT '号段的长度',
`version` int(20) NOT NULL COMMENT '版本号',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
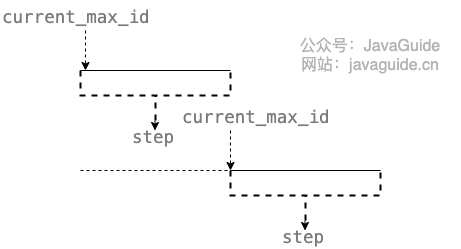
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;current_max_id 字段和step字段主要用于获取批量 ID,获取的批量 id 为:current_max_id ~ current_max_id+step。
数据库号段模式
version 字段主要用于解决并发问题(乐观锁),biz_type 主要用于表示业务类型。
2. 先插入一行数据。
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
VALUES
(1, 0, 100, 0, 101);3. 通过 SELECT 获取指定业务下的批量唯一 ID
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101结果:
id current_max_id step version biz_type
1 0 100 0 1014. 不够用的话,更新之后重新 SELECT 即可。
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101结果:
id current_max_id step version biz_type
1 100 100 1 101相比于数据库主键自增的方式,数据库的号段模式对于数据库的访问次数更少,数据库压力更小。
另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
数据库号段模式的优缺点:
- 优点:ID 有序递增、存储消耗空间小
- 缺点:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
NoSQL
Redis
一般情况下,NoSQL 方案使用 Redis 多一些。我们通过 Redis 的 incr 命令即可实现对 id 原子顺序递增。
127.0.0.1:6379> set sequence_id_biz_type 1
OK
127.0.0.1:6379> incr sequence_id_biz_type
(integer) 2
127.0.0.1:6379> get sequence_id_biz_type
"2"为了提高可用性和并发,我们可以使用 Redis Cluster。Redis Cluster 是 Redis 官方提供的 Redis 集群解决方案(3.0+版本)。
除了 Redis Cluster 之外,你也可以使用开源的 Redis 集群方案Codis (大规模集群比如上百个节点的时候比较推荐)。
除了高可用和并发之外,我们知道 Redis 基于内存,我们需要持久化数据,避免重启机器或者机器故障后数据丢失。Redis 支持两种不同的持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)。 并且,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
关于 Redis 持久化,我这里就不过多介绍。不了解这部分内容的小伙伴,可以看看 Redis 持久化机制详解这篇文章。
Redis 方案的优缺点:
- 优点:性能不错并且生成的 ID 是有序递增的
- 缺点:和数据库主键自增方案的缺点类似
MongoDB
除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。

MongoDB ObjectId 一共需要 12 个字节存储:
- 0~3:时间戳
- 3~6:代表机器 ID
- 7~8:机器进程 ID
- 9~11:自增值
MongoDB 方案的优缺点:
- 优点:性能不错并且生成的 ID 是有序递增的
- 缺点:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)